
@作者: 机器学习算法 @迪吉老农
最近使用GBDT时,想通过分布式进行训练,尝试了一些框架,但原理不太了解。有些东西与同事讨论后,也还不甚明了,于是专心看了一下文档,在此记录一下。
1、分布式原理
常用分布式训练方式,应该是参数服务器。worker把sample的统计结果推送到单台参数服务器机器上,参数服务器汇总��后,再推送到worker端。有点类似于单reducer的方式。
相比于参数服务器的中心化方案,这里提到的都是去中心化方案。
LightGBM与XGBoost的其中一个区别,是实现了真正的分布式,原因是LightGBM不依托hive,TaskManager之间可以暴露端口进行通信,而Hivemall依托Hive,只能实现无通信的分布式。
把这几种机制梳理一下,目前一共是4种方案,
- Bagging
- Feature Parallel
- Data Parallel
- Voting
其中,Bagging方式是不带通信机制的;另外三种则通过通信,做到了针对GBDT的分布式训练(好像可以类比,数据并行,模型并行?)
LightGBM文档建议,按照下面方式选择并行方式,
| #data is small | #data is large | |
|---|---|---|
| #feature is small | Feature Parallel | Data Parallel |
| #feature is large | Feature Parallel | Voting Parallel |
1.1、Bagging
完全非中心化的架构,通过Data Parallel的方式将数据打散为多份,分布式训练,最后训练多颗子树,在最终阶段进行Bagging输出。其实严格来说,这个不是GBDT分布式了,而是一个随机森林了。在Hivemall封装的XGB中,就是这样实现的。XGB的文档中,对于分布式的描述不多,没有看到其他带有通信机制的分布式的介绍。具体训练流程后面介绍。
1.2、Feature Parallel
�特征并行的训练方式,流程如下,
- 数据按列切分成不同的worker,
- 每个结点保留全部的数据,但分裂时只使用特定的特征,每个worker使用自己的feature进行分裂,输出候选的分裂集splits
- worker之间通信,选取gain提升最多的split,然后统一执行相同的split
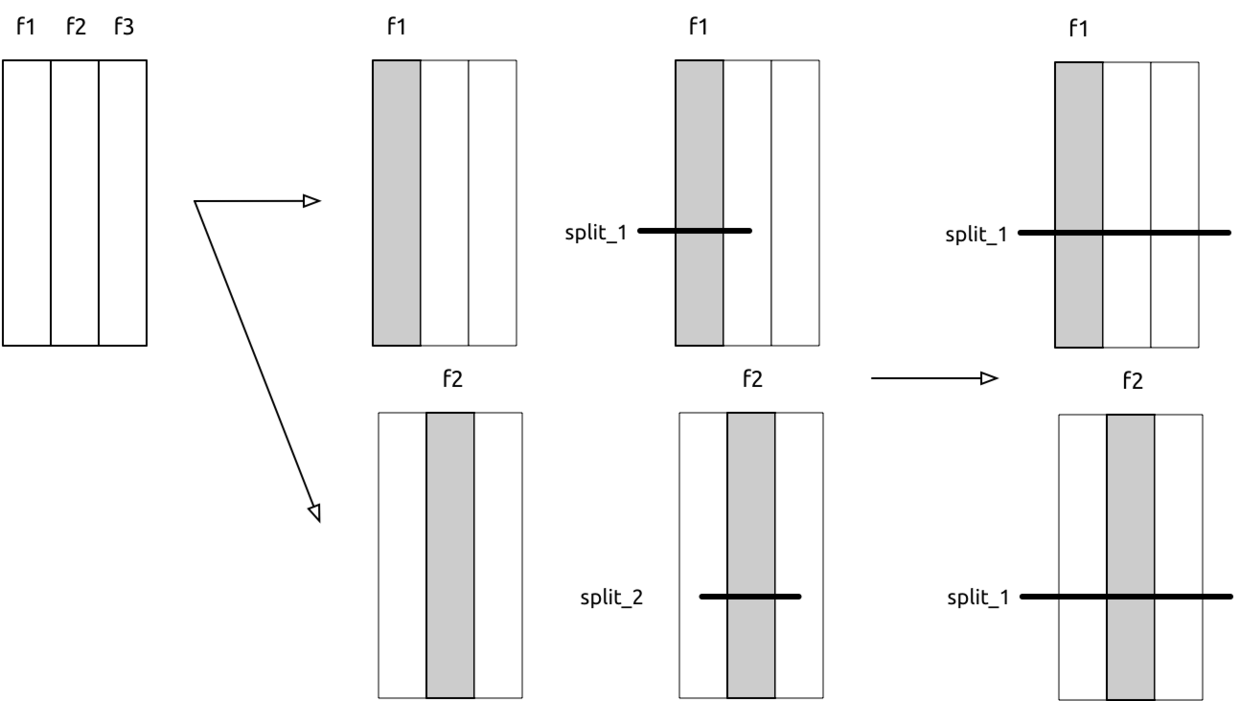
性能层面,由于每次分裂都是用全量数据,但是列变少了,所以数据量是瓶颈,时间复杂度O(#data)
1.3、Data Parallel
数据并行是类似于Bagging的方式,按照行进行分裂,区别是在于分裂点的计算上。Bagging的方式中,树与树之间是独立的,每棵树的分裂点都是只使用了1/n的数据计算的,前期的分裂应该还好,子样本与总样本之间统计差异不大,但是细分的时候可能就有点区别了。
数据并行下,每个worker统计自己的分裂点的数据,比如在一种分裂下,worker1内部:喜欢10人,不喜欢1人,worker2内部:喜欢5人,不喜欢2人,在汇总阶段就可以算出一种分裂下,整体是喜欢15人,不喜欢3人。注意,这还只是一种分裂,如果要考虑所有的分裂可能性,那这个计算和汇总工作就很大了。
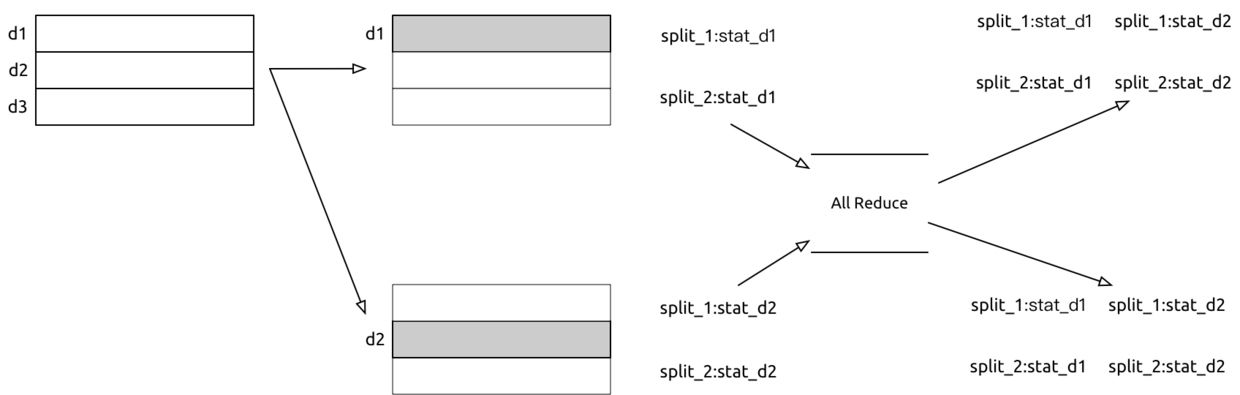
具体说下,汇总的这个操作,是采用All-reduce的方式(将每台机器的子样本结果,发送给所有机器,然后在每台机器上都reduce全部的子样��本;常规的reduce是把子样本结果发送给一台机器,在那台机器上汇总)。
这样的计算方式,通信成本的时间复杂度是O(2 * #feature * #bin)
LightGBM文档中是这么说,也没太看懂,估计会有常数倍的提升
Data Parallel in LightGBM
We reduce communication cost of data parallel in LightGBM:
- Instead of “Merge global histograms from all local histograms”, LightGBM uses “Reduce Scatter” to merge histograms of different (non-overlapping) features for different workers. Then workers find the local best split on local merged histograms and sync up the global best split.
- As aforementioned, LightGBM uses histogram subtraction to speed up training. Based on this, we can communicate histograms only for one leaf, and get its neighbor’s histograms by subtraction as well.
All things considered, data parallel in LightGBM has time complexity
O(0.5 * #feature * #bin).
1.4、Voting Parallel
近似算法,认为大样本情况下,局部最优分裂和整体最优分类是近似的。文献引用,摘要如下
Decision tree (and its extensions such as Gradient Boosting Decision Trees and Random Forest) is a widely used machine learning algorithm, due to its practical effectiveness and model interpretability. With the emergence of big data, there is an increasing need to parallelize the training process of decision tree. However, most existing attempts along this line suffer from high communication costs. In this paper, we propose a new algorithm, called Parallel Voting Decision Tree (PV-Tree), to tackle this challenge. After partitioning the training data onto a number of (e.g., ) machines, this algorithm performs both local voting and global voting in each iteration. For local voting, the top- attributes are selected from each machine according to its local data. Then, the indices of these top attributes are aggregated by a server, and the globally top- attributes are determined by a majority voting among these local candidates. Finally, the full-grained histograms of the globally top- attributes are collected from local machines in order to identify the best (most informative) attribute and its split point. PV-Tree can achieve a very low communication cost (independent of the total number of attributes) and thus can scale out very well. Furthermore, theoretical analysis shows that this algorithm can learn a near optimal decision tree, since it can find the best attribute with a large probability. Our experiments on real-world datasets show that PV-Tree significantly outperforms the existing parallel decision tree algorithms in the tradeoff between accuracy and efficiency.
2、训练方式
2.1、Hivemall调用XGBoost
训练数据的格式是以hive表的方式保存,格式如下
function create_dataset_on_emr() {
hive -e "
USE cv_weibo;
DROP TABLE IF EXISTS ${T_PRE}_xgb_input;
CREATE EXTERNAL TABLE ${T_PRE}_xgb_input (
row_id string,
features array<string> comment '特征数组',
label string comment '类目'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION '/yandi/iris/${T_PRE}_xgb_input'
;
"
}
训练过程,调用Java封装的UDAF函数
function train() {
hive -e "
use cv_weibo;
set hive.execution.engine=mr;
set mapred.reduce.tasks=10;
set mapreduce.job.maps=20;
set hivevar:shufflebuffersize=1000;
set hivevar:xtimes=10;
SET hivevar:hivemall_jar=hdfs://yandi/udf/hivemall-all-0.6.2-incubating.jar;
CREATE TEMPORARY FUNCTION train_xgboost AS 'hivemall.xgboost.XGBoostTrainUDTF' USING JAR '\${hivemall_jar}';
CREATE TEMPORARY FUNCTION rand_amplify as 'hivemall.ftvec.amplify.RandomAmplifierUDTF' USING JAR '\${hivemall_jar}';
CREATE TEMPORARY FUNCTION amplify as 'hivemall.ftvec.amplify.AmplifierUDTF' USING JAR '\${hivemall_jar}';
drop table if exists ${T_PRE}_xgb_softmax_model;
create table ${T_PRE}_xgb_softmax_model
as
select
train_xgboost(features, label,
'-objective binary:logistic -num_round 50 -num_early_stopping_rounds 30
-max_depth 5 -min_child_weight 2')
as (model_id, model)
from (
select
rowid, features, label
from
${T_PRE}_xgb_input
cluster by rand(43)
) shuffled;
"
}
训练出来的模型保存在一张hive表里,并且通过base64编码成了一个加密字符串。
预测阶段,将数据与模型表join在一起,使得每行都保存了完整的模型分裂信息。UDAF可以随时加载模型参数,实现数据并行化预测。如果在训练阶段,分成了多个reducer,则会生成多个子模型,在预测时可以选择其中一个,也可以选择所有结果进行bagging(代码里对应majority_vote)。如果训练阶段只设置了一个reducer,则这里只有一个单独模型
function predict() {
hive -e "
use cv_weibo;
set hive.execution.engine=mr;
SET hivevar:hivemall_jar=hdfs://yandi/udf/hivemall-all-0.6.2-incubating.jar;
CREATE TEMPORARY FUNCTION majority_vote as 'hivemall.tools.aggr.MajorityVoteUDAF' USING JAR '\${hivemall_jar}';
CREATE TEMPORARY FUNCTION xgboost_predict_one AS 'hivemall.xgboost.XGBoostPredictOneUDTF' USING JAR '\${hivemall_jar}';
drop table if exists ${T_PRE}_xgb_softmax_predicted;
create table ${T_PRE}_xgb_softmax_predicted
as
with yandi_tmp_sample as (
select * from ${T_PRE}_xgb_input
where rand() < 0.0001
)
select
rowid,
majority_vote(cast(predicted as int)) as label
from (
select
xgboost_predict_one(rowid, features, model_id, model) as (rowid, predicted)
from
${T_PRE}_xgb_softmax_model l
join yandi_tmp_sample r
on model_id > ''
) t
group by rowid;
"
}
这里有个技巧,由于模型表只有1行(n个bagging的模型则是n行),在预测阶段的worker数量会卡死在1,没有按照数据行数进行scale。经过多次尝试,通过join代替outer join,可以解决这个问题,join需要一个条件,于是加了一个一定会满足的条件。
2.2、分布式LightGBM
训练数据的格式是以hdfs文件的方式保存,格式需要是tsv,csv,或者空格分列的libsvm格式
dataset_lightgbm() {
hive -e "
INSERT OVERWRITE DIRECTORY 'viewfs://c9/yandi/iris/data'
select concat_ws(' ',
label,
concat_ws(' ', features)
)
from ${T_PRE}_xgb_input
"
}
训练过程,如果是本地单机,则可以运行命令行,
./LightGBM/lightgbm config=train.conf
配置文件如下,
# task type, support train and predict
task = train
# boosting type, support gbdt for now, alias: boosting, boost
boosting_type = gbdt
# application type, support following application
# regression , regression task
# binary , binary classification task
# lambdarank , lambdarank task
# alias: application, app
objective = binary
# eval metrics, support multi metric, delimite by ',' , support following metrics
# l1
# l2 , default metric for regression
# ndcg , default metric for lambdarank
# auc
# binary_logloss , default metric for binary
# binary_error
metric = binary_logloss,auc
# frequence for metric output
metric_freq = 1
# true if need output metric for training data, alias: tranining_metric, train_metric
is_training_metric = true
# number of bins for feature bucket, 255 is a recommend setting, it can save memories, and also has good accuracy.
max_bin = 255
# training data
# if exsting weight file, should name to "binary.train.weight"
# alias: train_data, train
data = data/000000_0
# validation data, support multi validation data, separated by ','
# if exsting weight file, should name to "binary.test.weight"
# alias: valid, test, test_data,
valid_data = data/000001_0
# number of trees(iterations), alias: num_tree, num_iteration, num_iterations, num_round, num_rounds
num_trees = 5
# shrinkage rate , alias: shrinkage_rate
learning_rate = 0.1
# number of leaves for one tree, alias: num_leaf
num_leaves = 15
# type of tree learner, support following types:
# serial , single machine version
# feature , use feature parallel to train
# data , use data parallel to train
# voting , use voting based parallel to train
# alias: tree
tree_learner = feature
# number of threads for multi-threading. One thread will use one CPU, defalut is setted to #cpu.
# num_threads = 8
# feature sub-sample, will random select 80% feature to train on each iteration
# alias: sub_feature
feature_fraction = 0.8
# Support bagging (data sub-sample), will perform bagging every 5 iterations
bagging_freq = 5
# Bagging farction, will random select 80% data on bagging
# alias: sub_row
bagging_fraction = 0.8
# minimal number data for one leaf, use this to deal with over-fit
# alias : min_data_per_leaf, min_data
min_data_in_leaf = 50
# minimal sum hessians for one leaf, use this to deal with over-fit
min_sum_hessian_in_leaf = 5.0
# save memory and faster speed for sparse feature, alias: is_sparse
is_enable_sparse = true
# when data is bigger than memory size, set this to true. otherwise set false will have faster speed
# alias: two_round_loading, two_round
use_two_round_loading = false
# true if need to save data to binary file and application will auto load data from binary file next time
# alias: is_save_binary, save_binary
is_save_binary_file = false
# output model file
output_model = output/LightGBM_model.txt
# support continuous train from trained gbdt model
# input_model= trained_model.txt
# output prediction file for predict task
# output_result= prediction.txt
# support continuous train from initial score file
# input_init_score= init_score.txt
# machines list file for parallel training, alias: mlist
machine_list_filename = lightGBMlist.txt
# max depth of tree
max_depth = 6
# early stopping
early_stopping_rounds = 5
# scale negative and positive weight
scale_pos_weight = 10
这里面涉及分布式的选项是tree_learner,需要填写 feature ,data, voting其中之一。
分布式提交,
train_lightgbm() {
bin/ml-submit \
--app-type "distlightgbm" \
--app-name "distLightGBM-yandi" \
--files train.conf,lightGBM.sh \
--worker-num 1 \
--worker-memory 10G \
--cacheArchive hdfs:/yandi/udf/LightGBM.zip#LightGBM \
--input-strategy DOWNLOAD \
--input viewfs://c9/yandi/iris/data#data \
--output /yandi/iris/output#output \
--launch-cmd "sh lightGBM.sh"
}
lightGBM.sh,只是在上面的配置文件后面增加了机器列表,是安装部署时配置好的,不用改
cp train.conf train_real.conf
chmod 777 train_real.conf
echo "num_machines = $LIGHTGBM_NUM_MACHINE" >> train_real.conf
echo "local_listen_port = $LIGHTGBM_LOCAL_LISTEN_PORT" >> train_real.conf
./LightGBM/lightgbm config=train_real.conf
需要改的参数是
worker-numworker-memoryinput:这句话是指定了一个目录映射,会把指定hdfs目录拉到worker节点,并将目录整体重命名为#后面的部分,对应train.conf中的data = data/000000_0和valid_data = data/000001_0output:也是一个目录映射,在训练完后,会把worker节点的目录output,就是#后面那部分,拷贝回到hdfs的目录上,对应train.conf中的output_model = output/LightGBM_model.txt
训练日志
21/06/22 14:15:10 INFO Container: Input path: data@[viewfs://c9/yandi/iris/data/000000_0, viewfs://c9/yandi/iris/data/000001_0, viewfs://c9/yandi/iris/data/000002_0, viewfs://c9/yandi/iris/data/000003_0, viewfs://c9/yandi/iris/data/000004_0]
21/06/22 14:15:10 INFO Container: Downloading input file from viewfs://c9/yandi/iris/data/000000_0 to data/000000_0
21/06/22 14:15:10 INFO Container: Downloading input file from viewfs://c9/yandi/iris/data/000001_0 to data/000001_0
21/06/22 14:15:10 INFO Container: Downloading input file from viewfs://c9/yandi/iris/data/000003_0 to data/000003_0
21/06/22 14:15:10 INFO Container: Downloading input file from viewfs://c9/yandi/iris/data/000004_0 to data/000004_0
21/06/22 14:15:31 INFO Container: PYTHONUNBUFFERED=1
21/06/22 14:15:31 INFO Container: INPUT_FILE_LIST=null
21/06/22 14:15:31 INFO Container: LIGHTGBM_NUM_MACHINE=1
21/06/22 14:15:31 INFO Container: LIGHTGBM_LOCAL_LISTEN_PORT=26628
21/06/22 14:15:31 INFO Container: TF_INDEX=0
21/06/22 14:15:41 INFO Container: Executing command:sh lightGBM.sh
21/06/22 14:15:41 INFO Container: [LightGBM] [Info] Finished loading parameters
21/06/22 14:15:41 INFO ContainerReporter: Starting thread to read cpu metrics
21/06/22 14:15:42 INFO ContainerReporter: Resource Utilization => Cpu: %0, Memory: 0.5G
21/06/22 14:15:51 INFO Container: [LightGBM] [Info] Finished loading data in 9.567071 seconds
21/06/22 14:15:51 INFO Container: [LightGBM] [Info] Number of positive: 53487, number of negative: 1228361
21/06/22 14:15:51 INFO Container: [LightGBM] [Info] Total Bins 4669
21/06/22 14:15:52 INFO Container: [LightGBM] [Info] Number of data: 1281848, number of used features: 22
21/06/22 14:15:54 INFO Container: [LightGBM] [Info] Finished initializing training
21/06/22 14:15:54 INFO Container: [LightGBM] [Info] Started training...
21/06/22 14:15:55 INFO Container: [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.041726 -> initscore=-3.133997
21/06/22 14:15:55 INFO Container: [LightGBM] [Info] Start training from score -3.133997
21/06/22 14:16:02 INFO ContainerReporter: Resource Utilization => Cpu: %249, Memory: 0.8G
21/06/22 14:16:14 INFO Container: [LightGBM] [Info] Iteration:1, training auc : 0.999878
21/06/22 14:16:14 INFO Container: [LightGBM] [Info] Iteration:1, training binary_logloss : 0.0841326
21/06/22 14:16:15 INFO Container: [LightGBM] [Info] Iteration:1, valid_1 auc : 0.999866
21/06/22 14:16:15 INFO Container: [LightGBM] [Info] Iteration:1, valid_1 binary_logloss : 0.0843192
21/06/22 14:16:15 INFO Container: [LightGBM] [Info] 20.487200 seconds elapsed, finished iteration 1
21/06/22 14:16:22 INFO ContainerReporter: Resource Utilization => Cpu: %502, Memory: 0.8G
21/06/22 14:16:23 INFO Container: [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
21/06/22 14:16:25 INFO Container: [LightGBM] [Info] Iteration:2, training auc : 0.999878
21/06/22 14:16:25 INFO Container: [LightGBM] [Info] Iteration:2, training binary_logloss : 0.0723086
21/06/22 14:16:27 INFO Container: [LightGBM] [Info] Iteration:2, valid_1 auc : 0.999866
21/06/22 14:16:27 INFO Container: [LightGBM] [Info] Iteration:2, valid_1 binary_logloss : 0.0724657
21/06/22 14:16:27 INFO Container: [LightGBM] [Info] 32.446888 seconds elapsed, finished iteration 2
21/06/22 14:16:34 INFO Container: [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
21/06/22 14:16:35 INFO Container: [LightGBM] [Info] Iteration:3, training auc : 0.999878
21/06/22 14:16:35 INFO Container: [LightGBM] [Info] Iteration:3, training binary_logloss : 0.0632701
21/06/22 14:16:36 INFO Container: [LightGBM] [Info] Iteration:3, valid_1 auc : 0.999866
21/06/22 14:16:36 INFO Container: [LightGBM] [Info] Iteration:3, valid_1 binary_logloss : 0.0634079
21/06/22 14:16:36 INFO Container: [LightGBM] [Info] 41.907969 seconds elapsed, finished iteration 3
21/06/22 14:16:42 INFO ContainerReporter: Resource Utilization => Cpu: %598, Memory: 0.8G
21/06/22 14:16:47 INFO Container: [LightGBM] [Info] Iteration:4, training auc : 0.99994
21/06/22 14:16:47 INFO Container: [LightGBM] [Info] Iteration:4, training binary_logloss : 0.0561602
21/06/22 14:16:48 INFO Container: [LightGBM] [Info] Iteration:4, valid_1 auc : 0.999929
21/06/22 14:16:48 INFO Container: [LightGBM] [Info] Iteration:4, valid_1 binary_logloss : 0.056288
21/06/22 14:16:48 INFO Container: [LightGBM] [Info] 53.568802 seconds elapsed, finished iteration 4
21/06/22 14:16:56 INFO Container: [LightGBM] [Info] Iteration:5, training auc : 0.999942
21/06/22 14:16:56 INFO Container: [LightGBM] [Info] Iteration:5, training binary_logloss : 0.0500692
21/06/22 14:16:58 INFO Container: [LightGBM] [Info] Iteration:5, valid_1 auc : 0.99993
21/06/22 14:16:58 INFO Container: [LightGBM] [Info] Iteration:5, valid_1 binary_logloss : 0.0501897
21/06/22 14:16:58 INFO Container: [LightGBM] [Info] 63.627517 seconds elapsed, finished iteration 5
21/06/22 14:16:58 INFO Container: [LightGBM] [Info] Finished training
21/06/22 14:16:59 INFO Container: worker_0 ,exit code is : 0
21/06/22 14:16:59 INFO Container: Output path: output#viewfs://c9/yandi/iris/output
21/06/22 14:16:59 INFO Container: Upload output output to remote path viewfs://c9/yandi/iris/output/_temporary/container_e38_1622178278006_5469657_01_000003 finished.
21/06/22 14:16:59 INFO Container: Container container_e38_1622178278006_5469657_01_000003 finish successfully
21/06/22 14:17:02 INFO ContainerReporter: Resource Utilization => Cpu: %0, Memory: 0.41G
21/06/22 14:17:07 WARN Container: received kill signal
21/06/22 14:17:07 INFO Container: Container exit
21/06/22 14:17:07 INFO Container: clean worker process
参考文献
版权声明
以上文章为本人@迪吉老农原创,首发于简书,文责自负。文中如有引用他人内容的部分(包括文字或图片),均已明文指出,或做出明确的引用标记。如需转载,请联系作者,并取得作者的明示同意。感谢。